
위즈wiz
ADsP 데이터 에듀 모의1 오답노트 본문
2번 문제
DIKW 피라미드의 계충 중 "B마트보다 상대적으로 저렴한 A마트에서 연필을 사야겠다"의 내용에 해당하는 계층은 무엇인가?
데이터(Data) : 객관적 사실, 측정값, 수치를 말함
정보(Information) : 데이터를 가공 및 처리하여, 데이터간 연관관계와 의미를 도출한 것을 정보
지식(Knowledge) : 다양한 정보를 구조화하여, 유의미한 정보를 분류하고 일반화시킨 결과물
지혜(Wisdom) : 지식을 축적하고 이해하면서 아이디어와 결합한 창의적인 산물을 지혜 혹시 통찰
DIKW예시
Data : 제품 x가 사이트 a에서 100원이다
Information : 제품 x는 사이트 a보다 사이트 b에서 더 비싸게 판매한다
Knowledge : 사이트 a에서 제품 x의 가격이 더 저렴하므로 구매할 계획이다
Wisdom : 사이트 a의 다른 제품들도 사이트 b보다 더 쌀 것으로 예상한다
데이터 : ~이다
정보 : 판매한다
지식 : 계획이다
지혜 : 예상한다
| 데이터Data | 정보Information | 지식Knowledge | 지혜Wisdom |
| - 객관적 사실 - 의미가 중요하지 않음 | - 데이터를 가공, 처리 - 데이터간 연관관계, 의미도출 - 의미가 유용하지 않을수도 | - 다양한 정보를 구조화 - 유의미한 정보를 분류 - 고유의 지식으로 내재화 | - 지식의 출적과 이해 - 지식 + 아이디어 결함 -> 창의적 산물 |
| 제품 x가 사이트 a에서 100원, 사이트 b에서 200원 | 제품 x는사이트 a보다 b에서 더 비싸게 판매함 | 사이트 a가 더 싸므로 제품 x를 사이트 a에서 구매할 계획 | 사이트 b의 타 제품도 사이트 a보다 더 비쌀것으로 예측 |
4번 문제
빅데이터 분석에 경제성을 제공해 준 결정적인 기술
- 클라우드 컴퓨팅(Cloud Computing)
클라우드 컴퓨팅은 보편화는 빅데이터의 처리 비용을 획기적으로 낮춰 경제성을 제공
6번 문제
여행사실을 트윗한 사람의 집을 강도가 노리는 고전적 사례가 발생했다. 이러한 사례를 통해 알 수 있는 빅데이터 시대의 위기 요인으로 적절한 것은?
1. 사생활 침해
ㅇ위기요인 : 개인정보를 다른 목적으로 사용하여 사생활 침해 발생, 데이터 익명화 기술의 발전이 필요
| 내용 | 개인정보가 포함된 데이터를 목적 외에 활용할 경우 사생활 침해를 넘어 사회/경제적 위협으로 변형될 수 있다. |
| 예시 | 여행 사실을 트윗한 사람의 집을 강도가 노리는 고전적 사례 발생 |
※ 개인정보 비식별화 기술
- 데이터 마스킹 : 홍길동 -< 홍**
- 가명처리 : 홍길동 -> 아무개
- 총계처리 : 홍길동 170cm, 아무개 180cm, 임꺽정 160cm -> 총 키합 510cm or 평균 170cm
- 데이터 범주화 : 홍길동, 35세 -> 홍씨 30~40세, 홍씨 30대
- 데이터 값 삭제 : 홍길동 35세, 서울 거주, 서울대 졸업 -> 35세, 서울 거주
- 잡음 첨가(노이즈 추가) : 자료에 잡음을 추가하여 변형을 주는 것
ㅇ통제요인 : 개인정보 사용을 제공자의 동의에서 사용자 책임으로
2. 책임 원칙 훼손
ㅇ 위기요인 : 빅데이터 기술이 발전하여 정확도가 증가하더라도, 분석 대상이 희생양이 될 수 있음
ex> 범죄 예측 프로그램을 통한 범죄 전 체포
ㅇ 통제요인 : 기존의 책임원칙 강화, 결과 기반 책임 원칙 고수(나타난 결과에 대해서만 책임 지우기)
ex> 범인을 잡을 때 "나는 빅데이터 기술이 예측한 대로 했을 뿐이야"라는 말로 희생양이 발생하는 것에 대한 면죄부를 받는 것을 방지하는 것이 중요하다"
| 내용 | 빅데이터 기본분석과 예측기술이 발전하면서 정확도는 증가한 만큼, 분석대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성도 증가한다. 민주주의 국가에서는 잠재적 위협이 아닌 명확한 결과에 대한 책임을 묻고 있어 이에 따른 원리를 훼손할 가능성이 있다. |
| 예시 | 영화 "마이너리티 리포트"에 나오는 것처럼 범죄 예측 프로그램에 의해 범행을 저지르기 전에 체포, 자신의 신용도와 무관하고 부당하게 대출이 거절되었다. > 민주주의 국가의 형사 처벌은 잠재적 위협이 아닌 명확한 행동 결과에 대해 책임을 묻고 있다. |
3. 데이터 오용
ㅇ 위기요인 : 빅데이터 분석이 항상 옳은 결과를 낳지는 않음
ㅇ 통제요인 : 데이터 알고리즘에 대한 접근권 허용 및 객곽적 인증 방안 도입 -> 알고리즈미스트 필요
* 알고리즈미스트 : 데이터 분석 알고리즘으로 부당한 피해를 보는 사람을 방지하기 위해 생겨난 직업
| 내용 | 빅데이터는 일어난 일에 대한 데이터에 의존하기 떄문에 이를 바탕으로 미래를 예측하는 것은 적지 않은 정확도를 가질 수 있지만 항상 맞을 수는 없다, 또한 잘못된 지표를 사용하는 것도 빅데이터의 폐해가 될 수 있다. |
| 예시 | 베트남 전쟁 맥나마라 장군은 적군 사망자 수를 전쟁의 진척 상황을 나타내는 지표로 활용했고 그 결과 적군 사망자 순 과장돼 보고되는 경향을 보여 결과적으로 전쟁항황을 오보하는 결과를 발생 |
결론
| 위기요인 | 통제방안 |
| 사생활 침해 | (개인정보) 제공자의 동의->사용자의 책임 |
| 책임 원칙 훼손 | 결과 기반(잠재적x) 책임원칙 고수 |
| 데이터 오용 | 알고리즘 접근 허용, 알고리즈미스트 필요 |
9번 문제
데이터 사이언티스트가 효과적인 분석 모델 개발을 위해 고려해야하는 사항으로 가장 부적절한 것은?
분석 모델의 정확성은 대부분 수집된 데이터 범위 내에서만 유효하다. 모델 범위 외 요인들을 판단하고자 하는 것은 부적절하며 심지어 큰 위험을 동반할 수 있다. 또한 지나치게 많은 과거 데이터를 모델에 포함하는 것은 글로벌 금융위기 사례에서 알 수 있듯이 모델의 정확성을 떨어뜨리기도 한다
데이터 사이언티스트가 효과적인 분석 모델 개발을 위해 고려해야하는 부분(GPT 답변)
- 문제 정의:
- 분석 모델이 해결하고자 하는 문제를 명확히 정의해야 합니다. 비즈니스 목표와 분석 목표가 일치하는지 확인해야 합니다.
- 데이터 수집 및 준비:
- 모델 개발에 필요한 데이터를 충분히 수집해야 합니다. 이때 데이터의 양, 품질, 다양성을 고려해야 합니다.
- 데이터 정제(Data Cleaning): 결측치 처리, 이상치 제거, 데이터 형식 통일 등 데이터 전처리를 철저히 해야 합니다.
- 탐색적 데이터 분석 (EDA, Exploratory Data Analysis):
- 데이터의 분포, 패턴, 관계 등을 파악하기 위해 EDA를 수행합니다. 이를 통해 데이터의 특성을 이해하고, 잠재적인 문제점을 발견할 수 있습니다.
- 특성 공학 (Feature Engineering):
- 모델의 성능을 향상시키기 위해 중요한 특성을 추출하거나 새롭게 생성합니다. 이를 통해 모델이 데이터를 더 잘 이해하고 학습할 수 있도록 돕습니다.
- 모델 선택 및 학습:
- 문제 유형 (분류, 회귀, 군집 등)에 따라 적절한 알고리즘을 선택합니다.
- 모델 학습 과정에서 하이퍼파라미터 튜닝을 통해 최적의 성능을 도출하도록 합니다.
- 모델 평가:
- 학습된 모델을 다양한 성능 지표(정확도, 정밀도, 재현율, F1 스코어 등)를 사용해 평가합니다.
- 교차 검증을 통해 모델의 일반화 성능을 평가하고, 오버피팅이나 언더피팅 여부를 확인합니다.
- 모델 해석 가능성:
- 모델의 예측 결과를 이해하고 설명할 수 있는지 확인해야 합니다. 특히 비즈니스 도메인에서 해석 가능성이 중요한 경우에는 설명 가능한 AI(XAI) 기법을 사용할 수 있습니다.
- 모델 배포 및 모니터링:
- 실시간으로 운영 환경에 모델을 배포하고, 지속적으로 성능을 모니터링해야 합니다. 새로운 데이터가 들어왔을 때 모델의 성능이 저하되지 않도록 주기적으로 재학습 및 업데이트를 해야 합니다.
- 윤리적 고려사항:
- 데이터 프라이버시와 보안 문제를 신경 써야 합니다. 데이터 사용 시 윤리적 문제나 법적 문제가 발생하지 않도록 주의해야 합니다.
- 협업 및 커뮤니케이션:
- 데이터 사이언티스트는 비즈니스 이해관계자와 지속적으로 소통하여 요구사항을 파악하고, 분석 결과를 명확히 전달해야 합니다.
10번 문제
1. WHERE
- 기능: 특정 조건을 만족하는 행(row)들을 필터링합니다.
- 사용 시점: 데이터를 선택할 때, 조건에 맞는 행만을 추출하고자 할 때 사용합니다.
2. ORDER BY
- 기능: 쿼리 결과를 특정 열(column)을 기준으로 정렬합니다.
- 사용 시점: 데이터가 특정 순서로 정렬되어야 할 때 사용합니다
3. GROUP BY
- 기능: 동일한 값을 가진 행들을 그룹으로 묶어 집계(aggregation) 함수를 적용할 수 있게 합니다.
- 사용 시점: 데이터를 그룹별로 집계하고자 할 때 사용합니다.
4. HAVING
- 기능: GROUP BY로 그룹화된 결과에 대해 조건을 필터링합니다.
- 사용 시점: 그룹화된 데이터에 조건을 적용하고자 할 때 사용합니다. WHERE 절과 달리, HAVING은 집계 함수의 결과에 대해 조건을 걸 수 있습니다.
요약
- WHERE: 행 필터링 (조건에 맞는 행만 선택)
- ORDER BY: 결과 정렬 (특정 열 기준으로 정렬)
- GROUP BY: 그룹화 (동일한 값을 가진 행들을 그룹으로 묶음)
- HAVING: 그룹화된 결과에 대한 조건 필터링 (집계 함수 결과에 조건 적용)
다만 where하고 having을 헷갈릴수 있는데 그럴땐 그룹함수의 유무를 확인하면 된다.
where은 그룹함수 미포함, having은 그룹함수 포함
11번 문제
| 분석의 방법(How)→ | known | Un-know | |
| 분석의 대상(What) ↓ | |||
| known | 최적화(Optimization) | 통찰(Insight) | |
| un-know | 솔루션(Solution) | 발견(Discovery) | |
- 최적화(Optimization) : 분석 대상 및 분석 방법을 이해하고 현 문제를 최적화의 형태로 수행
- 솔루션(Solution) : 분석 과제는 수행되고, 분석 방법을 알지 못하는 경우 솔루션을 찾는 방식으로 분석과제 수행
- 통찰(Insight) : 분석 대상이 불분명하고, 분석 방법을 알고 있는 경우 인사이트 도출
- 발견(Discovery) : 분석 대상, 방법을 모른다면 발견을 통하여 분석 대상 자체를 새롭게 도출
14번 문제, 19번 문제
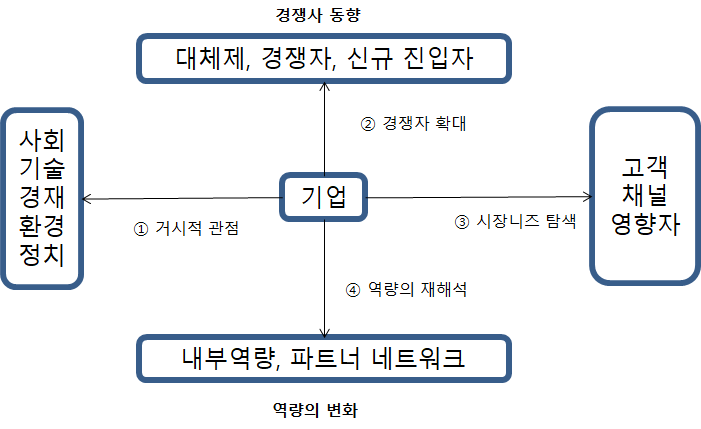
거시적 관점의 메가 트렌드: STEEP (social, technological, economic, enviromental, political)
- 경쟁자 확대 관점: 대체재, 경쟁자, 신규 진입자
- 시장의 니즈 탐색 관점: 고객, 채널, 영향자
- 역량의 재해석 관점: 내부 역량, 파트너와 네트워크
13문제, 15번 문제, 20번 문제
하향식 접근법(Top Down Approach)
- 문제탐색, 문제정의, 해결방안탐색, 타당성검토를 거쳐 분석과제 도출
1) 문제 탐색(Problem Discovery)
- 전체적인 관점의 기준 모델을 활용 빠짐없이 문제 식별이 중요
- 기업 내,외부의 비즈니스 모델과 외부 참조 모델이 존재
- 문제 해결시 발생하는 가치에 중점
가. 비즈니스 모델 기반 문제 탐색
- 업무, 제품, 고객 단위로 문제 발굴, 이를 규제와 감사, 지원 인프라영역으로 구분
- 업무(Operation) : 제품 생산의 내부 프로세스 및 주요자원 관련 주제 도출 / 생산 공정 최적화 등
- 제품(Product) : 제품을 개선하기 위해 주제 도출 / 주요기능 개선, 모니터링 지표 등
- 고객(Customer) : 제품, 서비스 제공 채널관점에서 도출 / 콜 대기시간 최소화, 영업점 위치 등
- 규제와 감사(Regualtion&Audit) : 생산 및 전달과정 중에서 발생하는 규제 및 보안의 관점에서 도출 / 품질이상 징후 등
- 지원 인프라(IT&Human Resource) : 인력 관점 / 적정 운영 인력 도출 등
나. 분석 기회 발굴의 범위 확장
① 거시적 관점의 메가 트렌드
- 사회(Social) : 시장의 사회적, 문화적 구조적 트렌드를 기반한 분석 / 노령화, 저출산 등
- 기술(Technological) : 최신기술의 변화에 따른 제품 개발 / 나노, IT융합, 로봇 등
- 경제(Economic) : 산업과 금융의 변동성 및 경제 구조 변화 동향 파악 / 원자재 가격, 금리 변동 등
- 환경(Environmental) : 환경과 관련된 정부, 시민단체 등의 관심과 동향 / 탄소 배출 규제 등
- 정치(Political) : 정책, 정세 등의 흐름을 토대로 분석 / 대북관계에 따른 원자재 구매 등
② 경젱자 확대 관점
- 대체재(Substitute) : 오프라인에서 온라인으로 제공하는 것에 대한 탐색 및 잠재적 위험 파악
- 경쟁자(Compertitor) : 경쟁자의 동향 파악하여 기회 도출
- 신규 진입자(NewEntrant) : 시장 파괴적인 신규 진입자의 동향 파악
③ 시장의 니즈 탐색 관점
- 고객(Customer) : 고객의 동향을 깊게 이해하여 제품 개선 / 철강-조선업, 자동차업
- 채널(Channel) : 영업사원, 대리점, 홈페이지 등의 탐색 / 은행-인터넷뱅킹
- 영향자(Influencer) : 기업의 의사결정에 영향을 미치는 관계자의 관심사항 파악 / 신규기업 인수
④ 역량의 재해석 관점
- 내부역량(Competency) : 지식 재산권, 기술력 등 재해석하고 탐색 / 소유 부동산을 활용
- 파트너와 네트워크(Partners&Network) : 관계사를 활용하여 수행 / 노하우를 활용
다. 분석 유즈 케이스
- 유사, 동종 사례를 탐색
2) 문제 정의(Problem Definition)
- 비즈니스 문제를 데이터 문제로 변환
- 필요 데이터 및 기법을 정의하는 단계
- 최종 사용자의 관점에서 이루어져야됨
3) 해결방안 탐색(Solution Search)
- 문제 해결을 위한 다양한 방안 모색 : 엑셀등 간단한 도구로 가능한지, 하둡 등 분산 병렬처리를 활용
- 분석 역량이 없을 시, 전문업체, 교육 등을 통해 해결 방안을 검토
4) 타당성 검토(Feasibility Study)
- 경제적 타당성 : 비용대비 편인 분석 관점의 접근
- 데이터 및 기술적 타당성 : 시스템 환경 및 분석 역량
상향식 접근법(Bottom Up Approach)
- 원천 데이터로부터 분석하여 지식을 얻는 방식
- 디자인 사고(Design Thinking) : Why보다 What의 관점으로 분석 - 공감, 정의, 설계, 프로토타입, 테스트
- 비지도 학습과 지도 학습
가) 비지도 합습(Unsuperbised Learning)
- 명확한 목적보다 연관성, 결합도 등을 중심으로 데이터 표현
- 장바구니 분석, 군집 분석, 기술 통계 및 프로파일링 등
나) 지도학습(Supervised Learning)
- 명확한 목적의 데이터 분석
- 인과관계 분석에서 상관관계 분석으로 문제 해결
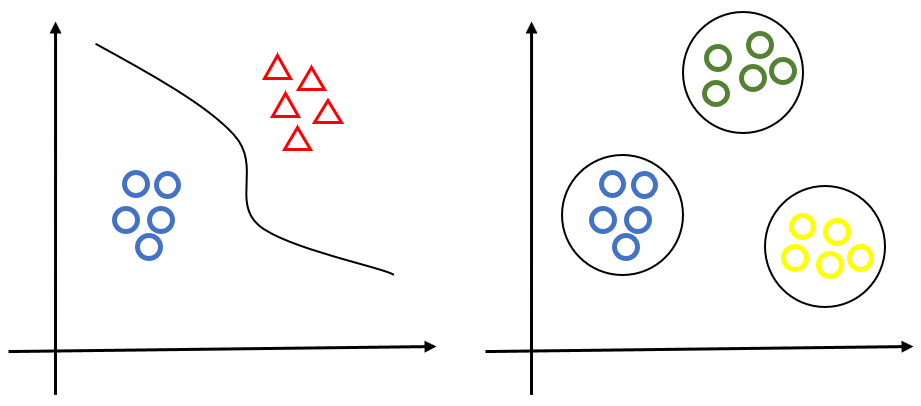
지도학습과 비지도학습 예시
- 시행착오를 통한 프로토타이핑 접근법
- 우선 분석을 실행 후 그 결과를 토대로 반복적으로 개선해 나가는 방법
- 프로세스 : 가설->디자인 실험->테스트->통찰
- 문제가 불명확할떼 이해를 도움
- 불가능한 프로젝트의 리스크 감소
- 기존의 데이터 정의를 재검토하여 사용 목적과 범위 확대
4. 분석과제 정의
- 분석과제 정의서 : 소스 데이터, 분석방법, 데이터 입수 및 분석난이도, 분석 주기, 분석 결과, 검증 오너십, 상세 분석 과정 등 정의
16번 문제
분석 프로젝트 영역별 주요 관리 항목 (10가지)
- 1) 범위 (Scope)
- 분석 기획단계에서 프로젝트의 범위가 데이터의 형태와 양 또는 적용되는 모델의 알고리즘에 따라 범위가 빈번하게 변경됨
- 분석의 최종 결과물이 분석 보고서 or 시스템 -> 투입되는 자원 및 범위가 크게 변경 -> 사전 충분히 고려
- 2) 시간 (Time)
- 지속적으로 반복, 많은 시간 소요
- 분석 결과에 대한 품질이 보장된다는 전제 -> Time Boxing 기법으로 일정관리 진행 필요
- 3) 원가 (Cost)
- 외부 데이터 활용인 경우 고가의 비용 소요될 수도 -> 사전 조사 필
- 오픈 소스 도구 (Tool) 외에 의도했던 결과 달성을 위해 상용 버전의 도구가 필요할 수도
- 4) 품질 (Quality)
- 수행 결과에 대한 품질목표를 사전에 수립, 확정해야
- 품질통제(Quality Control)와 품질보증(Quality Assurance)으로 나누어 수행
- 5) 통합 (Integration)
- 프로젝트관리 프로세스들이 통합적으로 운영될 수 있도록 관리
- 6) 조달 (Procurement)
- 외부 소싱 적절 운영 필요
- PoC (Proof of Concept) 형태의 프로젝트는 인프라 구매 아닌 클라우드 등 다양 방안 검토
- 7) 자원 (Resource)
- 인력 공급 부족 -> 수행 전 전문가 확보 검토
- 8) 리스크 (Risk)
- 데이터 미확보
- 데이터 및 분석 알고리즘의 한계 -> 품질목표 달성 어려움
- 9) 의사소통 (Communication)
- 결과가 모든 프로젝트 이해관계자가 공유할 수 있도록
- 다양한 의사소통체계 마련
- 10) 이해관계자 (Shareholder)
- 다양한 전문가 팜여 -> 이해 관계자의 식별과 관리 필요
17번 문제
분석 과제 관리 프로세스 수립
분석 마스터 플랜이 수립되고 초기 데이터 분석 과제가 성공적으로 수행되는 경우, 지속적인 분석 니즈 및 기회가 분석과제 형태로 도출될 수 있다. 이런 과정에서 분석 조직이 수행할 중요한 역할 중 하나가 분석과제의 기획 및 운영이므로 이를 체계적으로 관리하기 위한 프로세스를 수립해야 한다.
- 분석 조직이 지속적이고 체계적인 분석 관리 프로세스를 수행함으로써 조직 내 문화 내재화 및 경쟁력을 확보할 수 있다.
- 해당 과제를 진행하면서 만들어진 시사점을 포함한 결과물을 풀(pool)에 달 축적하고 관리 함으로써 향후 유사한 분석과제 수행시 시행착오를 최소화하고 프로젝트를 효율적으로 진행 가능

18번 문제
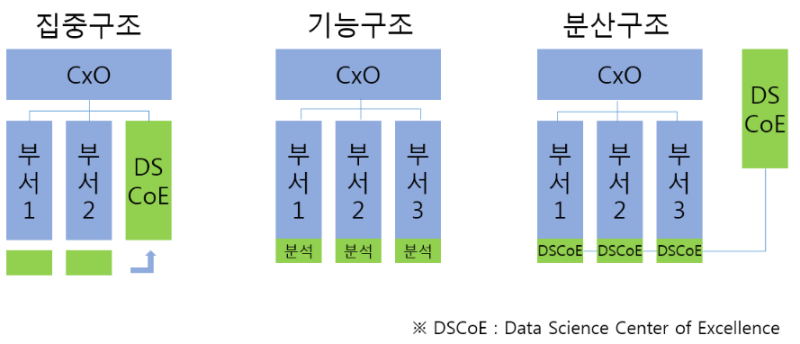
⑴ 집중구조 : 전사 분석 업무를 별도의 분석 전담 조직에서 담당
⑵ 기능구조 : 해당 업무 부서에서 분석 수행, 전사적 차원 X
⑶ 분산구조 : 분석조직 인력을 현업부서로 직접 배치, 전사적 차원 O, 업무과다 이원화 가능성
23번 문제
R은 시험에 안나오므로 패스
24번 문제
모분산의 추론
- 이표본에 의한 분산비 검정은 두 표본의 분산이 동일한지 비교하는 검정으로 검정통계량은 F분포를 따른다.
- 모분산이 추론의 대상이 되는 경우는 모집단의 변동성 또는 퍼짐의 정도에 관심이 있을 때다.
- 모집단이 정규분포를 따르지 않더라도 중심극한 정리를 통해 정규 모집단으로부터의 모분산에 대한 검정을 유사하게 할 수 있다.
- 평균 모집단에서 n개를 단순임의 추출한 표본의 분산은 자유도가 n-1인 t분포를 따른다→ (x) 카이제곱분포
25번 문제
| 구분 | 설명 | 장점 | 단점 |
| 전진선택법 (forward) | 절편만 있는 상수모형으로부터 시작해 중요하다고 생각되는 설명변수부터 차례로 모형에 추가 | 전진선택법은 이해하기 쉽고 변수의 개수가 많은 경우에도 사용가능 | 변수값의 작은 변동에도 그 결과가 크게 달라져 안정성이 부족 |
| 후진제거법 (backward) | 독립변수 후보 모두를 포함한 모형에서 출발해 가장 적은 영향을 주는 변수부터 하나씩 제거하면서 더 이상 제거할 변수가 없을 때의 모형을 선택 | 후진제거법은 전체 변수들의 정보를 이용하는 장점이 있음 | 변수의 개수가 많은 경우 사용하기 어려움 |
| 단계선택법 (stepwise) | 전진선택법에 의해 변수를 추가하면서 새롭게 추가된 변수에 기인해 기존 변수의 중요도가 약화되면 해당 변수를 제거하는 등 단계별로 추가 또는 제거되는 변수의 여부를 검토해 더 이상 없을때 중단 |
4번 선지 최적선택법이라는 것은 없고 이것은 단계선택법에 대한 부분의 내용입니다.
26번 문제
이상치 판정 방법
- IQR 계산:
- IQR=Q3−Q1IQR = Q3 - Q1
- 이상치의 기준 계산:
- 하한 기준: Q1−1.5×IQRQ1 - 1.5 \times IQR
- 상한 기준: Q3+1.5×IQRQ3 + 1.5 \times IQR
- 이상치 식별:
- 데이터 값이 하한 기준보다 작거나 상한 기준보다 큰 경우, 해당 데이터 값은 이상치로 간주됩니다.
2번 선지는 3시그마 법칙으로 상자그림에서 사용되지 않는 법칙입니다.
27번 문제
연속형 확률분포(연속확률분포)
- 정규분포
- 균일분포
- 지수분포
- t-분포
- 카이제곱 분포(X^2분포)
- F-분포
이산형 확률분포(이산확률분포)
- 베르누이 확률분포
- 이항분포
- 기하분포
- 초기화분포
- 다항분포
- 포아송분포
28번 문제
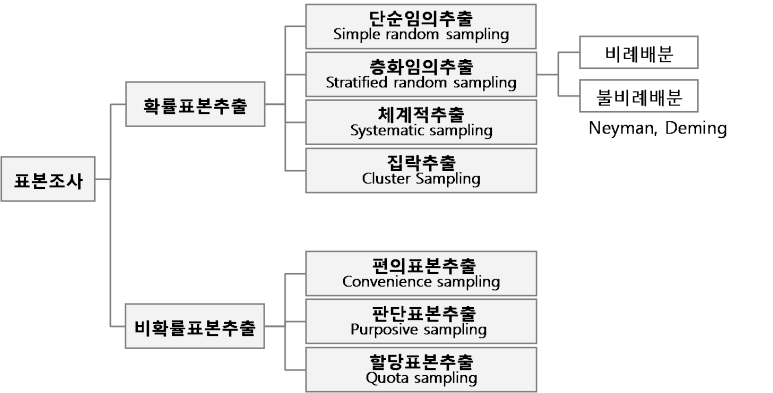
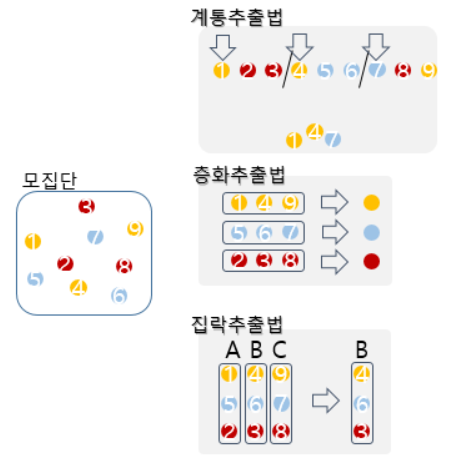
계통추출법 : 추출틀에서 처음 k번째 단위들 중 하나를 랜덤하게 출발점으로 선택한 다음, 그 점으로 부터 매k번째 떨어진 간격에 위치하는 단위를 추출한 표본
ex> 5, 15, 25, 35, 45
29번 문제
비모수 검정
| 통계기법 | 변수의 척도 | 사용목적 |
| χ2 검정 | 명목/서열 | 두 변수들간의 독립성 검정 |
| 스피어만 상관계수 | 서열 | 두 변수들간의 상관관계 추정 |
| Run 검정 | 명목 | 관찰된 자료의 무작위성 검토 |
| Kolmogorov-Smirnov (단일표본검정) |
등간/비율 | 관찰값들의 분포 추정 (표본자료가 이론적으로 가정한 확률분포에서 나왔는지를 검정) |
| Kolmogorov-Smirnov (독립 2표본검정) |
서열화* | 두 집단의 분포 비교 (두 표본들이 동일한 확률분포를 갖는 모집단으로부터 추출되었는지에 대한 검정) |
| Mann-Whitney U 검정 | 서열화 | 두 집단의 분포 비교 (두 표본들이 동일한 확률분포를 갖는 모집단으로부터 추출되었는지에 대한 검정) |
| Kruskal-Wallis 검정 | 서열화 | 세 집단 이상의 분포 비교 (k개의 표본들이 상이한(혹은 동일한) 모집단으로부터 추출되었는지에 대한 검정 |
| Wilcoxon 검정 | 서열화 | 대응되는 두 집단간의 순위 비교 |
| Friedman 검정 | 서열화 | 대응되는 두 집단 이상의 순위 비교 |
| Kendall 검정 | 서열화 | 여러 평가내용들간의 일치성 검토 |
| Binomial 검정 | 명목 | 이항분포 변수의 기대빈도와 관찰빈도 비교
[출처] 비모수통계의 의미와 종류|작성자 구미랑
|
4번 선지 자기상관검정이란 시계열 분석에서 쓰이는것
30번 문제
| 구분 | 피어슨 상관분석 | 스피어만 상관분석 |
| 자료형태 | 모수 | 비모수 |
| 자료 척도 | 등간 척도, 비율 척도 | 서열 철도 |
피어슨 상관분석
모든 변수가 연속형이고 정규분포를 띄는 경우에 사용할 수 있음
두 변수가 얼마나 선형적인 관계를 가지는지의 정도
모수적 방법
A 변수가 증가하는 추세이고, B 변수가 증가하는 추세이면 corresltation은 1에 가까워진다. (범위: -1 ~ 1)
변수 예시: 신장, 몸무게
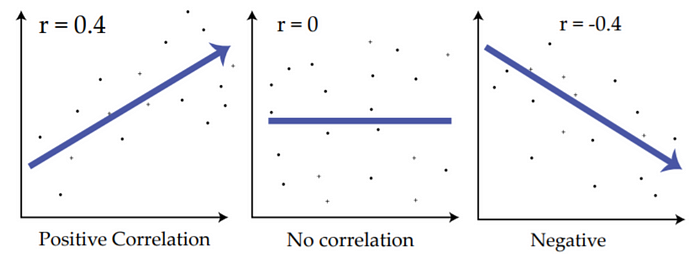
r = 0일때, 상관관계가 없다고 볼 수 있다.
비선형 상관관계
서열변수간 상관 계수를 추정하는 방식
비모수방법
변수 예시: 졸업학위, 성적등급
스피어만 상관계수
스피어만 상관계수는 변수들의 순위 간의 상관성을 측정
일반적으로 켄달의 순위 상관계수보다 큰 값을 가짐
편차를 기반으로 한 계산함
데이터의 오류 및 불일치에 훨씬 더 민감함
31번 문제
결정계수란?
결정계수는 두 변량사이의 상관계수 r의 제곱인 r²을 의미한다. 결정계수라 불리는 이유는 다른 변수, x가 주어졌을 때 r²은 한 변수 y의 분산에 비례하기 때문이다. 이는 E(Y)=a+bx와 같은 회귀모형에서 y의 전체 분산이 x에 의해 설명되는 정도를 나타내 주기 때문이다. 일반적으로 다중회귀에서는 여러 독립변수와 종속변수와의 사이에 존재하는 중상관계수를 R이라 하고 R²을 결정계수라고 하며, 이를 결정지수라고도 한다.
따라서 종속변수에 미치는 영향이 적더라도 독립변수가 추가되면 결정계수는 변한다
32번 문제
시계열 자료는 대부분 비정상 자료이며, 비정상 자료를 차분, 회귀분석, 평활법을 통해 정상 시계열로 만든 후 시계열 분석을 실시한다
ARIMA(2,1,3) : 1번의 차분을 통해 ARMA(2,3)이라는 정상성 데이터를 만든다
33번 문제
일반적으로 평균이 일정하지 않은 비정상 시계열은 차분을 통해, 분산이 일정하지 않은 비정상 시계열은 변환을 통해 정상시계열로 바꾼다
34번 문제
이런 문제는 항상 등분산성을 위배했다고 볼 수 있음
35번 문제
36번 문제
데이터 마이닝(data mining)은 대규모로 저장된 데이터 안에서 체계적이고 자동적으로 통계적 규칙이나 패턴을 분석하여 가치있는 정보를 추출하는 과정이다. 다른 말로는 KDD(데이터베이스 속의 지식 발견, knowledge-discovery in databases)라고도 일컫는다.
데이터 마이닝의 활용분야
- 데이터베이스 마케팅(Database Marketing)
- 데이터를 분석하여 획득한 정보를 이용하여 마케팅 전략 구축
- 예:
- 목표마케팅(Target Marketing)
- 고객 세분화(Segmentation)
- 이탈고객분석(Churn Analysis)
- 장바구니 분석(Market Basket Analysis)
- 상품추천 등…
- 신용평가 (Credit Scoring)
- 특정인의 신용상태를 점수화하는 과정
- 신용거래 대출한도를 결정하는 것이 주요 목표
- 이를 통하여 불량채권과 대손을 추정하여 최소화함
- 예: 신용카드, 주택할부금융, 소비자 / 상업 대출
- 생물정보학 (Bioinformatics)
- 지놈(Genome)프로젝트로부터 얻은 방대한 양의 유전자 정보로부터 가치 있는 정보의 추출
- 응용분야: 신약개발, 조기진단, 유전자 치료
- 텍스트 마이닝 (Text Mining)
- 디지털화된 자료 (예: 전자우편, 신문기사 등)로 부터 유용한 정보를 획득
- 응용분야: 자동응답시스템, 소셜미디어 분석, 상품평 분석, 전자도서관, Web surfing
- 부정행위 적발 (Fraud Detection)
- 고도의 사기행위를 발견할 수 있는 패턴을 자료로부터 획득
- 응용분야 : 신용카드 거래사기 탐지, 부정수표 적발, 부당/과다 보험료 청구 탐지
데이터마이닝 적용사례
- 소매/유통업
- 미국의 할인점 Wall Mart에서 매장내의 상품들과 고객들의 구매패턴의 연관성을 발견하기 위하여 연관성 분석 알고리즘을 사용
- 기저귀와 맥주가 강한 연관성을 나타냄
- 기저귀와 맥주를 가까이 배치하여 매출이 증가
신용카드회사-----
- 국내의 한 신용카드회사가 부정행위를 적발하고 이를 예방하기 위한 모형의 구축
- 기존의 카드 소지자의 구매패턴을 분석하여 현재의 구매패턴이 카드 소지자의 구매패턴과 틀린 경우 부정사용으로 의심
- 의사결정나무와 신경망 모형, 딥러닝 기법등이 사용됨
- 카드의 부정사용 방지를 통하여 고객의 자산 보호 및 회사의 손해액 감소
-----
- 의료분야
- 종양의 악성/양성 판단에 의한 암 진단의 정확성을 높이기 위한 판별 및 분류분석 시행
- 과거의 환자들에 대해서 종양검사의 결과를 근거로(즉, 종양의 크기, 모양, 색깔 등) 종양의 악성/양성 여부를 구별하는 분류모형을 만든 후, 새로운 환자에서 얻은 입력변수를 이용하여 암을 진단
- 지도학습방법 (신경망, 로지스틱 회귀모형, 의사결정나무 등)이 사용
제조업-----
- 반도체회사에서 불량품 자동검색장치 개발
- 연관성 분석과 군집분석 알고리즘을 사용
- 정상인 반도체를 그 특성에 기반하여 몇 개의 군집으로 나눈 후, 새로운 제품이 정상제품의 군집의 범위밖에 있는 경우 불량으로 규정
- 불량품 감소로 인한 이익의 증대
통신회사-----
- 미국의 한 장거리 통신 회사의 23%의 고객이 매년 이탈
- 새로운 고객 한명을 유치하는데 필요한 비용이 $350
- 이탈고객관리(churn management)와 군집분석(clustering)을 이용하여 이탈의 원인을 파악 현재 고객의 40%가 이탈 가능성이 높음
- 이익분석(profit analysis)를 통하여 이탈가능성이 높은 고객을 상대로 한 마케팅이 효과적임이 입증
- 무료 통화서비스 등의 목표마케팅(target marketing)으로 이탈고객 감소와 이를 통한 이익의 증가
38번 문제
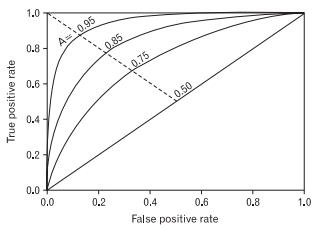
ROC 커브:
ROC(Receiver Operating Characteristic) Curve는 모든 분류 임계값에서 분류 모델의 성능을 보여주는 그래프로 x축이 FPR(1-특이도), y축이 TPR(민감도)인 그래프이다. 즉 민감도와 특이도의 관계를 표현한 그래프이다.
39번 문제
k평균법은 계층적 군집방법과는 달리 한 개체가 속해있던 군집에서 다른 군집으로 이동해 재배치가 가능하다. 초기값에 의존하는 방법으로 군집의 초기값 선택에 따라 최종 군집이 변할
계층적 군집 (Hierarchical Clustering)
- 군집의 개수가 정해지지 않았을 때 사용합니다. 군집의 개수를 모를 때 사용하기 때문에 몇 개의 군집으로 나누어야 하는지 결정하기 위해 사용하기도 합니다.
- 가까운 개체끼리 차례로 묶거나 멀리 떨어진 개체를 차례로 분리하는 방법으로 합병에 의한 방법(agglomerative)과 분할에 의한 방법 (divise)이라고 합니다.
- 구현이 간단하고 이해하기 쉬우며, 덴드로그램과 같은 그래프로 결과를 직관적으로 이해할 수 있습니다.
- 한 번 병합된 개체는 다시 분리되지 않는다는 특징을 가지고 있습니다.
- 군집의 특성을 설명하기가 애매한 경우도 발생합니다. 사용된 거리측정 방법과 알고리즘에 따라 아웃라이어에 민감도가 높거나, 큰 사이즈의 군집을 잘라버리는 경우도 발생하는 경우가 있기 때문입니다.
- 많은 변수를 투입하거나 데이터의 크기가 많은 경우 계산량이 많아 느립니다.
수 있다.
K-Means 군집 분석
이 프로시저를 사용하면 여러 개의 케이스를 다루는 알고리즘을 통해 선택한 특성을 기준하여 상대적으로 동질적인 케이스 그룹을 구별할 수 있습니다. 그러나 이러한 알고리즘을 사용하려면 군집의 수를 지정해야 합니다. 이러한 정보를 알 경우에는 군집중심초기값을 지정할 수 있습니다. 케이스를 분류하려면 반복적으로 군집중심을 업데이트하거나 분류만 하는 두 가지 방법 중 하나를 선택할 수 있습니다. 소속군집, 거리 정보, 마지막 군집중심 등을 저장할 수 있습니다. 선택적으로 케이스별 결과를 설명하는 데 사용되는 값을 갖는 변수를 지정할 수 있습니다. 분산 분석 F 통계가 필요할 수도 있습니다. 이러한 통계는 필요에 따라 사용할 수 있으며(이 프로시저는 서로 다른 그룹을 구성하려고 함) 통계의 상대적 크기로 그룹 분리에 각 변수가 미치는 영향을 알 수 있습니다.
예. 각 그룹에서 비슷한 시청자 유형을 갖는 텔레비전 쇼를 구별하는 그룹은 무엇입니까? K-평균 군집 분석을 사용하면 텔레비전 쇼(케이스)를 시청자의 특성에 따라 K 동일성 그룹으로 모을 수 있습니다. 이 방법은 마케팅을 위한 대상 선정에도 사용됩니다. 다양한 마케팅 전략을 검정하는데 비교 도시들을 선택할 수 있도록 도시(케이스)를 동일 그룹으로 모을 수 있습니다.
통계. 완료 해법에 대해 군집중심초기값, 분산 분석표를 선택할 수 있습니다. 각 케이스에 대해 군집 정보, 군집중심으로부터의 거리를 선택할 수 있습니다.
K-Means 군집 분석 데이터 고려 사항
데이터. 변수는 구간 수준이나 비율 수준에서 양적변수이어야 합니다. 사용 변수가 이분형이나 개수일 경우 계층적 군집 분석 프로시저를 사용합니다.
케이스 및 군집중심 초기값 순서. 군집중심 초기값을 선택하는 기본값 알고리즘은 케이스 순서에 따라 달라질 수 있습니다. 반복 대화 상자의 유동계산 평균 사용 옵션을 사용하면 군집중심 초기값의 선택 방법과 상관없이 케이스 순서에 따라 결과 해법이 달라질 수 있습니다. 이러한 방법 중 하나를 사용하는 경우 주어진 해법의 안정성을 확인하기 위해 케이스를 각기 다른 무작위 순서로 정렬하여 서로 다른 여러 가지 해법을 구할 수도 있습니다. 군집중심 초기값을 지정하고 유동계산 평균 사용 옵션을 사용하지 않으면 케이스 순서와 관련된 문제를 방지할 수 있습니다. 그러나 케이스에서 군집중심까지의 거리가 동률인 경우 군집중심 초기값의 순서가 해법에 영향을 줄 수 있습니다. 주어진 해법의 안정성을 평가하기 위해 중심 초기값의 순열을 각기 달리하여 실행한 분석 결과를 비교할 수 있습니다.
가정. 거리는 단순 유클리드 거리를 사용하여 계산합니다. 다른 거리나 유사성 측도를 사용하려면 계층적 군집 분석 프로시저를 사용합니다. 변수 척도화는 특히 중요한 고려 사항입니다. 한 변수는 달러로 표시되고 다른 변수는 연도로 표시되는 경우와 같이 변수가 서로 다른 척도로 측정되면 결과가 잘못될 수 있습니다. 이러한 경우에는 변수를 표준화한 후 K-평균 군집 분석을 수행하도록 합니다. 이 작업은 기술통계 프로시저에서 수행할 수 있습니다. 이 프로시저에서는 적합한 군집의 수를 선택했으며 관련 변수가 모두 포함되었다고 가정합니다. 선택한 군집의 수가 적합하지 않거나 중요 변수가 빠졌을 때는 결과가 잘못될 수 있습니다.
42번 문제
Examination 변수가 유의하지 않다
43번 문제
44번 문제
민감도=재현율
실재 : 실제로 TRUE이면 재현율(민감도)
예정 : 예상이 TRUE이면 정밀도
|
|
예상 값
|
||
|
TRUE
|
FALSE
|
||
|
실
제
값
|
Positive
|
TP
|
FN
|
|
Negative
|
FP
|
TN
|
|
|
민감도 (Sensitivity)
|
(TP / TP + FN)
양성 중 맞춘 양성의 수
|
|
특이도 (Specificity)
|
(TN / FP + TN)
음성 중 맞춘 음성의 수
|
|
정밀도 (Precision)
|
(TP / TP + FP)
양성이라고 판정 한 것 중에 실제 양성 수
|
|
재현율 (Recall)
|
(TP / TP + FN)
전체 양성 수에서 검출 양성 수
|
|
정확도 (accuracy)
|
(TP + TN / TP + FN + FP + TN)
전체 개수 중에서 양성과 음성을 맞춘 수
|
45번 문제
주성분의 개수는 고윳값, 누적 기여율, 스크로 플롯을 통해 확인 가능, 고유치 분해 가능 여부는 주성분 개수를 정하는 방법이 아님
46번 문제
군집 분석에서는 군집의 개수나 구조에 대한 가정없이 제이터들 사이의 거리를 기준으로 군집화를 유도
48번 문제
시계열 분석
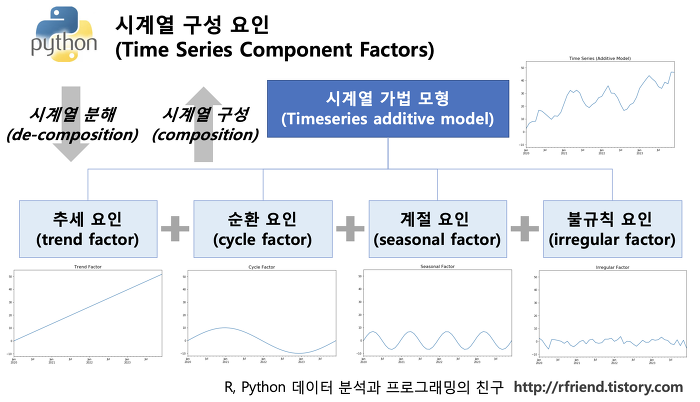
- 추세 : 인구의 변화, 자원의 변화, 자본재의 변화, 기술의 변화 등 같은 요인들에 의해 영향을 받는 장기변동 요인으로서, 급격한 충격이 없는 한 지속 되는 특성을 지님
Ex> "10년 주기의 세계경제 변동 추세" 같은 것이 추세 요인의 예시 - 계절 : 12개월의 주기를 가지고 반복되는 변화를 말하며, 계절의 변화, 공휴일의 반복, 추석 명절의 반복 등과 같은 요인들에 의하여 발생
- 순환 : 경제활동의 팽창과 위축과 같이 불규칙적이며 반복적인 중기 변동 요인을 뜻, 만약 관측한 데이터 셋이 10년 미만일 경우 추세요인과 순환 요인을 구분하는 것이 매우 어렵습니다. 그래서 관측 기간이 길지 않을 경우 추세와 순환 요인을 구분하지 않고 그냥 묶어서 추세 요인이라고 분석
- 불규칙 : 일정한 규칙성을 인지할 수 없는 변동의 유형을 의미, 천재지변, 전쟁, 질병 등과 같이 예상할 수 없는 우연적 요인에 의해 발생되는 변동을 의미. 불규칙변동은 경제활동에 미미한 영향을 미치기도 하지만 때로는 경제활동에 엄청난 영향을 주기도 함
49번 문제
인공신경망
- 인공신경망은 역전파 알고리즘 동일 입력층에 대한 원하는 값이 출력되도록 개개의 가중치(weight)를 조정하는 방법으로 사용
- 인공신경망은 이상치 잡음에 민감하지 않다
- 다층신경망은 단층신경망에 비해 훈련이 어렵다
- 은닉층 노드의 수가 너무 적으면 네트워크가 복잡한 의사결정 경계를 만들 수 없다
- 은닉층 노드의 수가 너무 많으면 일반화가 어렵다
- 은닉층의 수와 은닉노드 수의 결정은 자동으로 설정되지 않는다
- 은닉층의 은닉노드가 많아지면 과대적합, 적으면 과소적합
- 가중치가 0이면 선형 모델이 된다
- 훈련자료에 배깅을 적용하여 최종 예측치를 선정
50번 문제
사분위수 범위 : 사분위수 범위는 자료 집합의 중간 50%에 포함되는 자료의 산포도를 나타냅니다.
제 1사분위수(Q1) 와 제 3사분위수(Q3) 사이의 거리
사분위수범위 = Q3-Q1
중앙값 : 중앙. 모든 데이터를 크기 순으로 정렬해서 가운데에 있는 데이터를 선택 (가운데에 있는 데이터가 둘이라면 두 수의 평균)
평균 : 수의 "평균". 모든 수를 더하고 수의 개수로 나눠서 구하는 것
표준편차 : 통계집단의 분산의 정도 또는 자료의 산포도를 나타내는 수치로, 분산의 음이 아닌 제곱근즉, 분산을 제곱근한 것으로 정의된다. 표준편차가 작을수록 평균값에서 변량들의 거리가 가깝다.
'공부 > ADsP' 카테고리의 다른 글
| 데이터에듀 31회 오답노트 (0) | 2024.08.04 |
|---|---|
| 데이터 에듀 ADsP 30회 오답 노트 (0) | 2024.08.02 |
| 데이터 에듀 39회 오답노트 (0) | 2024.07.26 |
| ADsP 4장 2절 기초 통계분석 (0) | 2024.06.27 |
| ADsP 3과목 4장 3절 회귀분석 (0) | 2024.06.27 |

