
위즈wiz
데이터 에듀 ADsP 30회 오답 노트 본문
2번 문제
다음 중 빅데이터 활용사례로 부적절한 것은?
1번 이유 : 정형화가 아니라 정형, 비정형, 반정형 모두 수집하기 때문
3번 문제
다음 중 미래 사회의 특성과 빅데이터 역할이 올바르게 연결되지 않는 것은?
4번 이유 : 경쟁력과 연결되어 있는것은 단순화가 아닌 스마트이기 때문
4번 문제
다음중 빅데이터의 활용으로 알맞지 않은 것은?
1번 이유 : 빅데이터와 관련있는것은 맞으나 활용이 아니기 때문에
6번 문제
다음 중 데이터 베이스의 일반적인 특징이 아닌 것은?
1번 선지 : 통합데이터
2번 선지 : 저장데이터
3번 선지 : 공유데이터
4번 선지 : 변경되지 않는 데이터
통합데이터 : 여러곳에서 사용하던 데이터를 통합하여 하나로 저장된 데이터를 의미. 데이터의 중복을 최소화함
저장데이터 : 컴퓨터 저장 장치에 저장된 데이터 의미
공용(공유)데이터 : 공동으로 사용되는 데이터를 의미, 어느 순간이라도 둘 이상의 프로그램 또는 사람이 동시에 사용 가능
실시간 접근성 : 데이터가 실시간으로 서비스 된다
변화하는 데이터 : 데이터 베이스에 저장된 내용은 어느 한 순간의 상태를 나타내지만 데이터 값은 시간에 따라 항상 바뀌지만 정확한 데이터를 유지
동시 공유 : 데이터 베이스는 서로 다른 업무 또는 여러 사용자에게 동시에 공유된다
내용에 따른 참조 : 데이터 값을 사용하여 조건을 제시하면 데이터 베이스는 이에 해당하는 데이터를 검색해준다
7번 문제
다음 중 빅데이터 가치 산정이 어려운 이유는 무엇인가?
데이터의 활용 방식 : 데이터 활용 방식에서는 재사용이나 재조합, 다목적용 데이터 개발등이 일반화 되면서 특정 데이터를 언제, 어디서, 누가 활용할지 알 수 없게 되었다. 따라서 가치를 산정하는 것도 어려워졌다
새로운 가치 창출 : 빅데이터 시대에는 데이터가 기존에 없었던 가칠 창출함에 따라 그 가치를 측정하기가 어려워졌다
분석 기술 발전 : 현재는 가치가 없는 데이터일지라도 추후에 새로운 분석 기법이 등장한다면 거대한 가칠 지닌 데이터가 될 수 있다
결론:
2번 선지 이유 : 가치창출이 쉬워짐에 따라 가치를 산정하기 어려우기 때문에 틀린 선지
8번문제
아래는 특정 산업의 일차원적 분석 사례를 나열한 것이다. 다음 중 특정 산업으로 적절한 것은?
소매업 : 판촉, 매대관리, 수요예측, 재고 보충, 보증서 분석, 맞춤형 상품 개발, 신상품 개발
에너지 : 프레이딩, 공급/수요예측
운송업 : 일정 관리, 노선 배정, 수익 관리
금융서비스 : 신용점수 산정, 사기 탐지, 가격 책정, 프로그램 트레이딩, 클레임 분석, 고객수익성분석
그 밖에 나올 수 있는 것들
제조업 : 공급사실 최적화, 수요에측, 재고 보충, 보증서 분석, 맞춤형 상품 개발, 신상품 개발
병원 : 가격 책정, 고객 로열티, 수익 관리
정부 : 사기탐지, 사례관리, 범죄 방지, 수익 최적화
온라인 : 웹 매트릭스, 사이트 설계, 고객 추천
9번 문제
다음 중 아래의 데이터 거버넌스 체계가 설명하는 항목은?
데이터 표준화 : 데이터 표준용어 설정, 명명수칙 수립, 메타 데이터 구축, 데이터 사진 구축
데이터 관리 체계 : 메타데이터 관리, 데이터 사전관리, 데이터 생명주기 관리
데이터 저장소 관리 : 메타데이터 및표준 데이터를 관리 하기 위한 전사차원의 저장소
표준화 활동 : 데이터 거버넌스 체계구축 후 표준 준수 여부를 주기적으로 점검
11번 문제
다음 중 하향식 접근법에서 문제 탐색단계에 대한 내용 중 틀린 것은?
1번 이유 : 과제 발굴 단계에서는 세부적인 구현 및 솔루션에 초점을 맞추는게 아니라, 문제를 해결함으로써 발생하는 가치에 중점을 두는 것이 중요하다
12번 문제
지속적인 분석 내재화를 위한 장기적인 마스터 플랜 방식에 비하여 과제 중심적인 접근 방식 특징으로 가장 적절하지 못한 것은?
| 과제 중심적인 접근방식(과제 단위) (빠르다) | 장기적, 지속적 분석 내재화(마스터플랜 단위) (느리다) |
| 빠르게 해결하는 것이 목적 | 지속적인 분석 내재화가 목적 |
| speed & Test | Accuracy & Deploy |
| Quick & win | Long tern view |
| Problem Solving | Problem Definition |
외울때
과(제)
스(피드)
테(스트)
이(윈)
퀵
솔빙(Problem Solving)
마(스터)
정(확도)
문(문제정의)
롱(텀뷰)
과스테이퀵솔빙
마정문롱
14번 문제
전략적 중요도, 비즈니스 성과 및 ROI, 분석 과제의 실행 용의성
15번 문제
아래는 분석 방안 구체화에 대한 설명이다. 알맞은 단계를 선택하면?
의사결정 요소 모형화 :
- 분석 컨텍스트 간 상관관계를 모형화함(의사결정을 위한 요소간 관계를 구체화)
- 의사결정 요소 모형화를 통해 분석의 핵심 이슈와 의사결정을 위한 필요 요소를 한 장의 그림으로 분명하게 설명 가능
분석 체계도출:
- 정의된 의사결정 모형의 분석 컨 텍스트별로 수행할 분석을 정리하여 의사결정을 위한 전체 분석 세트와 관계를 도출함
- 각 분석들의 관계와 집합은 의사결정을 위한 시그널 허브로 작동
- 중간단계의 분석 결과들도 의사결정자들에게 필요한 시그널로 제공
- 지속적으로 보완되는 과정을 거쳐 의사결정 모형의 분석 체계 확정
분석 필요 데이터 정의:
- 분석 체계에 따라 분석에 필요한 데이터 및 데이터 유형을 식별하여 현재 기업에서 보유한 데이터와 외부에서 확보해야할 데이터를 정의
- 데이터 확보의 가능성과 비용 요인을 고려하여 향후 분석의 우선순위와 범위를 조정할 때 활용
분석 ROI 평가
- 분석 기회를 정의하고 필요한 분석을 도출한 것을 업무 의사결정에 분석을 활용함으로써 의사결정의 적시 정확성을 높이고 업무적 성과를 효과적으로 하고자 함이다. 즉 분석에 대한 경제성 평가를 꼭 점검해야함
16번 문제
분석 준비도는 기업의 데이터 분석 도입의 수준을 파악하기 위한 진단방법으로 6가지 영역을 대상으로 파악한다. 아래 보기의 내용의 어떤 영역의 내용인가?
분석 기법
- 업무별 적합한 분석기법
- 분석업무 도입 방법론
- 분석기법 라이브러리
- 분석기법 효과성 평가
- 분석기법 정기적 개선
분석 인력 및 조직
- 분석전문가 직무 존재
- 전문가 교육훈련 프로그램
- 관리자 기본 분석 능력
- 전사총괄 조직
- 경영진 분석 업무 이해
분석 데이터
- 분석 업무를 위한 데이터 충분성/신뢰성/적시성
- 비구적 데이터 관리
- 외부데이터 활용 체계
- 기준데이터 관리
분석업무 파악
- 발생한 사실 분석 업무
- 예측 분석 업무
- 시뮬레이션 분석 업무
- 최적화 분석 업무
- 분석 업무 정기적 개선
분석 문화
- 사실에 근거한 의사결정
- 관리자의 데이터 중심
- 회의 등에서 데이터 활용
- 직관보다 데이터 활용
- 데이터 공유 및 협업 문화
IT 인프라
- 운영시스템 데이터 통합
- EAI, ETL등 데이터 유통체계
- 분석 전용 서버 및 스토리지
- 분석환경(빅데이터/통계/비쥬얼)
17번 문제
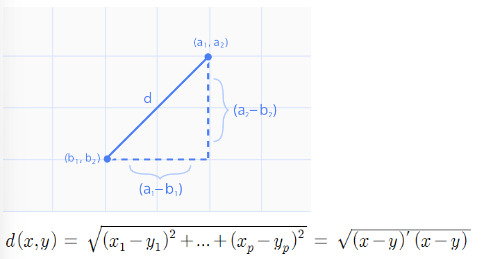
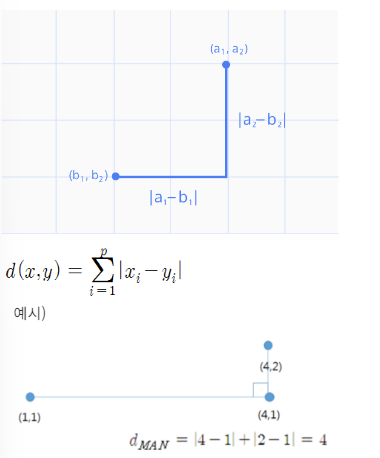
민코우스키 거리는 맨하탄 거리와 유클리디안 거리를 한번에 표현한 공식이다. 다음 중 민코우스키 거리를 나타내는 수식으로 올바른 것은?
1번 선지 : 유클리디안 거리
2번 선지 : 체비셰프 거리

3번 선지 : 맨하탄 거리
4번 선지 : 민코우스키 거리
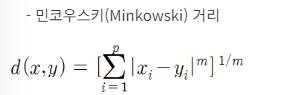
18번 문제
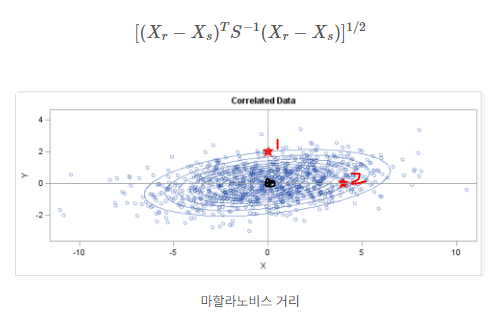
계층적 군집방법은 두 개체(또는 군집) 간의 거리(또는 비유사성)에 기반하여 군집을 형성해 나가므로 거리에 대한 정의가 필요한데, 마음 중 변수의 표준화와 변수 간의 상관성을 동시에 고려해 통계적 거리로 적절한 것은?
표준화 거리 : 두 점이 단위가 다를 때, 산포가 큰 특정 변수의 영향을 줄이기 위해 각 변수의 분산으로 나누어표준화한 값들의 유클리드 거리이다. 이 거리는 각 변수의 분산을 고려한 통계적 거리이다.
민코우스키 거리 : 유클리디안 거리, 맨하튼 거리, 체비셰프 거리 등의 거리 척도와 같은 단점들이 있기 때문에 각각들에 대해 이해하는 것이 중요하다. 매개변수 p이 있기 떄문에 적절한 p값을 찾기에 어려움이 있을 수도 있다. 하지만 p값을 통해 가장 적합한 걸리 측정 값을 찾을 수 있고 적합한 p값을 안다면 적절한 거리 척도를 사용할 수 있다.
마할라노비스 거리 : 각 변수의 분산과 공분산(상관성) 구조를 함께 고려한 통계적 거리이다. 유클리드 거리로 생각해보면 중심-점의 1거리가 점2의 거리보다 가깝다. 하지만 마할라노비스 거리는 변수들의 상관관계가 거리에 영향을 미친다. 확률등고선을 보면 중심점으로부터의 관측될 가능성이 더 높은 점2와의 거리가 더 가깝다고 생각한다.
19번 문제
앙상블 모형은 여러 모형의 결과를 결합함으로써 단일 모형으로 분석했을때보다 신뢰성 높은 예측값을 얻을 수 있다. 다음 중 앙상블 모형의 특징으로 옳지 않은 것은?
특징 :
1. 성능을 분산 시키기 때문에 과대적합 감소 효과가 있다.
2. 개별 모델 성능이 잘 안나올 때 앙상블 학습을 이용하면 성능이 향상될 수 있다.
3. 각 모형의 상호 연관성이 떨어질수록 정확도가 향상된다.(앙상블이므로 서로간의 연관성이 떨어져야 정확도가 향상된다)
4. 이상값에 대한 대응력이 높아지고, 전체 분산을 감소시켜 정확도를 상승시킨다.
5. 다양한 모형의 예측 결과를 결합함으로써 단일 모형으로 분석했을 때보다 높은 신회성을 가진다.
6. 모형의 투명성이 떨어지게 되어 정확한 현상의 원인 분석에는 부적합하다.
7. 앙상블은 학습 알고리즘들을 따로 쓰는 경우에 비해 더 좋은 예측 성능을 얻기 위해 다수의 학습 알고리즘을 사용하는 기법이다.
8. 주어진 자료로부터 여러 개의 예측 모형을 만든 후 예측 모형들을 조합하여 하나의 최종 예측 모형을 만드는 방법으로 다중 모델 조합, 분류기 조합이 있다.
9. 앙상블 알고리즘은 여러개의 학습 모델을 훈련하고 투표를 통해 최적화된 예측을 수행하고 결정한다
21번 문제
Hitters 데이터셋은 메이저리그의 선수 322명에 대한 타자 기록으로 20여개의 변수를 포함하고 있다. 아래 회귀모형에서 변수 선택을 하기 위한 결과물의 일부이다. 다음 중 결과물에 대한 설명으로 부적절한 것은?
1번, 4번 선지 : 후진제거법에 대한 설명
2번 선지 : stmodel<-lm(Salary~., data=Hitters) 에서 .이 모든 설명변수를 의미
3번 선지 : AIC에 대한 설명
AIC는?
AIC값이 낮을수록 좋다
해당 부분에서 AIC보다 큰 변수가 8개이므로 해당 변수들이 다음 step에서 제외된다
22번 문제
Defaulf 데이터셋은 10000명의 신용카드 고객에 대한 카드대금 연체여부, 카드 대금납입 후 남은 평균 카드잔고, 연봉, 학생여부를 포함한다. 아래는 연체 가능성을 모형화 하기 위한 로지스틱 회귀분석 결과이다. 다음 중 유의수준 0.05하에서 아래에 대한 설명으로 가장 부적절한 것은?
INCOME은 DEFAULT를 설명하는데 통계적으로 유의하지 않다(0.71152)
23번 문제
로지스틱 회귀분석은 독립변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계기법이다. 다음 중 로지스틱 회귀모형의 모형 검정 방법으로 알맞은 것을 고르시오
최소제곱법 : 구하려는 구하려는 해와 실제 해의 오차의 제곱의 합이 최소가 되는 해를 구하는 방법(회귀분석)
양측 검정 : 가설검정에서 검정량이 기각치 이하거나 이상이면 귀무가설을 기각하는 검정(가설검정)
F-검정 : 두 집단간 분산의 차이를 비교하여 그 차이가 유의한지 검정하는데 사용(분산검정)
카이제곱 검정 : 로지스틱 회귀모형의 모형 검정은 카이제곱 검정
24번 문제
다음 중 주성분 분석에서 변수의 중요도 기준이 되는 값은 무엇인가?
고윳값과 고유벡터
주성분 분석에서 고윳값과 고유벡터의 의미
고유벡터는 주성분(p)와 표준화된 독립변수(z)사이의 관계를 보여준다.
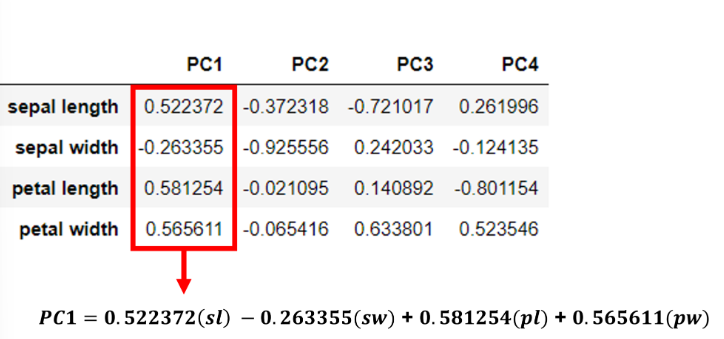
고윳값
각 주성분의 분산과 고윳값은 일치한다. 따라서 고윳값을 각 주성분이 담고 있는 데이터의 정보량이라고 볼 수 있다. 표준화된 데이터는 각 축(변수)의 정보량(분산)이 1로 동일했으나, 주성분들은 각자 나타내는 정보량이 다르다
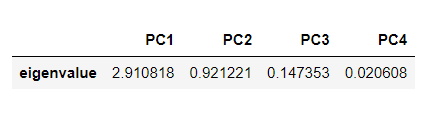
26번 문제
다음 중 회귀분석의 결과 중 잔차분석에서 만족해야하는 가정으로 맞는 것은?
선형성, 독립성, 등분산성, 정규성
28번 문제
확률이란 특정사건이 일어날 가능성의 척도라고 정의할 수 있다. 통계적 실험을 실시할 때 나타날 수 있는 모든 결과들의 집합을 표본공간이라고 하며, 사건이란 표본공간의 부분집합을 말한다. 다음 중 확률 및 확률분포에 대한 설명으로 가장 부적절한 것은?
1. 모든 사건의 확률값은 0과 1사이에 있다
2. 서로 배반인 사건들의 합집합의 확률은 각 사건들의 확률의 합이다.
3. 두 사건 A,B가 독립이라면 사건 B의 확률은 A가 일어난다는 가정하에서의 B의 조건부확률과 동일하다.
4번 선지 <- 연속형 확률밀도함수에 대한 설명
31번 문제
적합된 회귀모형의 안정성을 평가하기 위한 통계적 방법을 영향력 진단이라 한다. 자료에서 특정 관측치가 제외됨에 따라 분석 결과의 주요 부분에 많은 변동이 있다면 안정성이 약하다고 판단된다. 다음중 각 개체의 영향력 진단에 대한 설명으로 가장 부적절한 것은?
DFFITS는 절대값이 공식에 대입한 값보다 큰 값이 나타나야 높은 영향력으로 간주한다
32번 문제
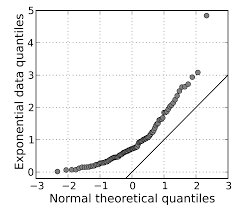
다음 중 데이터의 정규성을 확인하기 위한 방법으로 부적절한 것은?
히스토그램
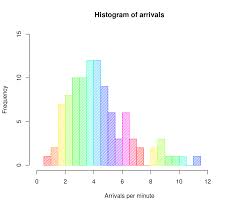
Q-Q 플룻
Shapiro-wilk test
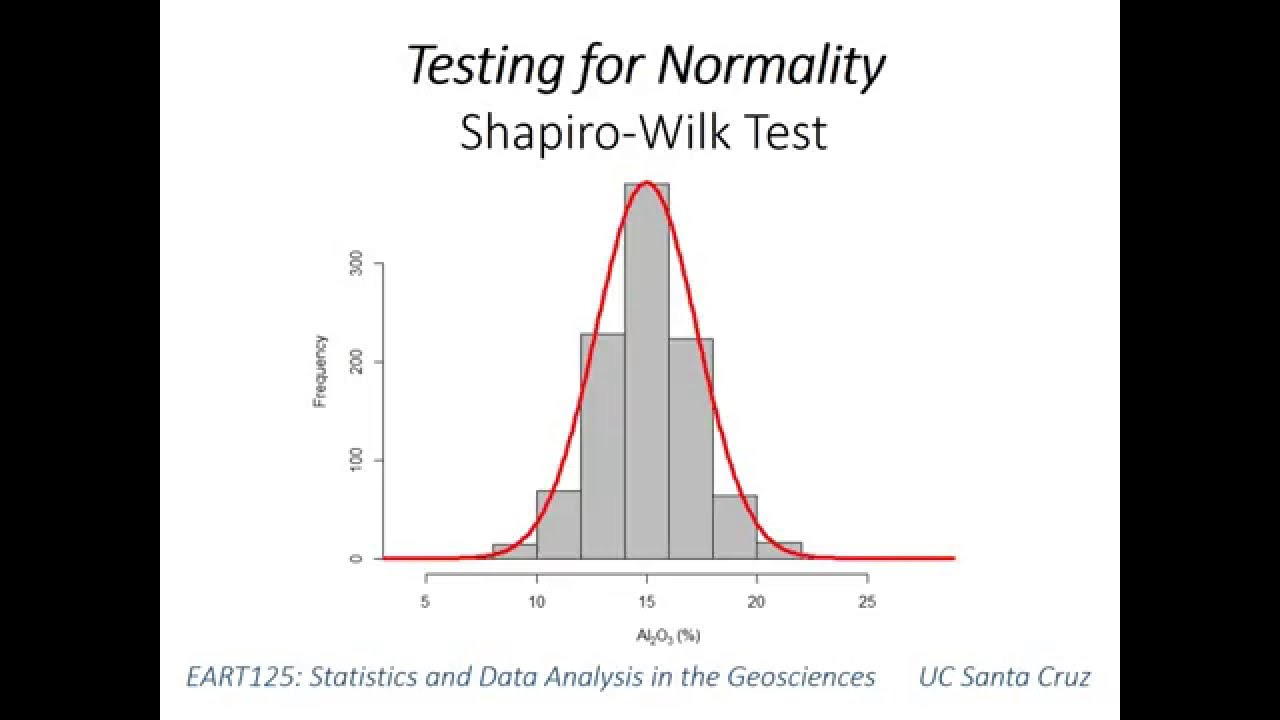
Durbin watson test - 시계열 부분으로 회귀 모형 오차항의 자기상관이 있는지에 대한 검정
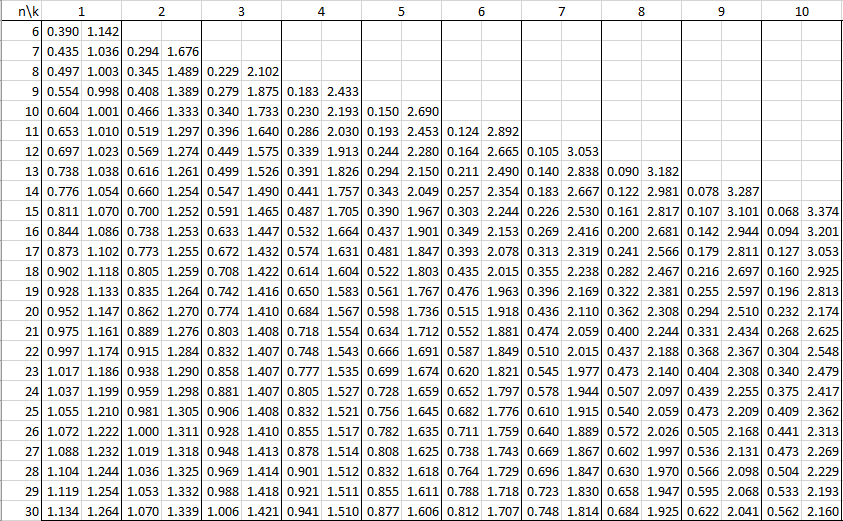
33번 문제
다음 제 1종 오류에 대한 설명 중 올바른 것은?
34번 문제
데이터 전처리 과정에서 이상치를 어떻게 처리할지 결정할 때 이상치를 판정하는 방법을 사용할 수 있다. 다음 중 상자그림을 이용하여 이상치를 판정하는 방법에 대한 설명으로 가장 부적절한 것은?
- IQR 계산:
- IQR=Q3−Q1IQR = Q3 - Q1
- 이상치의 기준 계산:
- 하한 기준: Q1−1.5×IQRQ1 - 1.5 \times IQR
- 상한 기준: Q3+1.5×IQRQ3 + 1.5 \times IQR
- 이상치 식별:
- 데이터 값이 하한 기준보다 작거나 상한 기준보다 큰 경우, 해당 데이터 값은 이상치로 간주됨
다만 2번 선지는 3시그마 법칙으로 상자그림에서 사용되지 않는 법칙
35번 문제
70명의 실험자를 대상으로 A,B 두 종류의 수면 유도제 복영 전과 후의 평균 체중 비교에 대한 분석을 수행하고 있다. 90% 신뢰구간을 구하고자 할 때. 아래의 빈칸 (가),(나)에 순서대로 들어갈 숫자를 고르시오
70명의 실험자 ->70
90% 신뢰구간 -> 0.1
하지만 + 또는 -가 있다면(단측검정) 10이지만 +-가 같이 쓰이면(양측검정) 0.05로 되어야 한다.
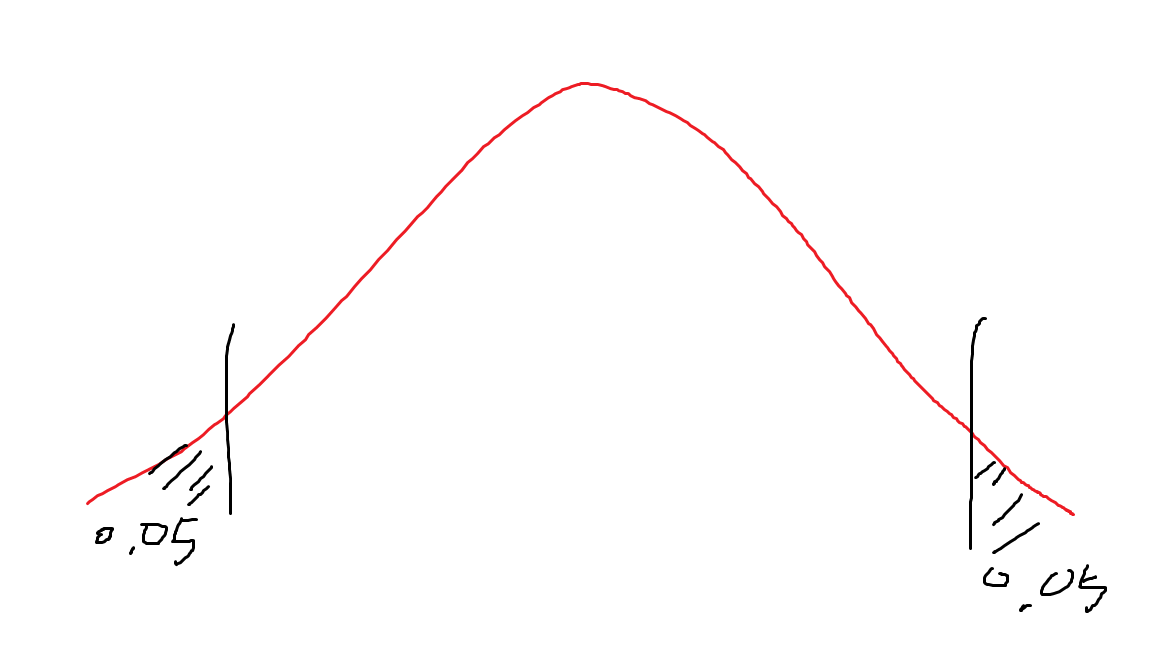
36번 문제
사회 관계망 모형에서 연결망 내 전체 구성원들이 서로 얼마나 많은 관계를 맺고 있는지를 나타내며, SNS내에서 존재하는 가능한 총 관계 수 중에서 실제로 맺어진 관계의 수를 비율로 계산하는 기법은?
사회 연결망이란?
- 개인 또는 집단이 하나의 노드가 되고, 그들 간의 관계는 링크로 표현
- 즉 사회 연결망은 이 각 노드들 간의 상호의존적인 관계에 의해 만들어지는 사회적 관계 구조
- 사회 연결망의 개념 활용 : SNS
사회 연결망 분석의 주요 요소들
- 중심성 : 한 행위자가 전체 연결망에서 중심에 위치하는 정도
- 중심성이 높은 사람은 높은 정보력을 획득할 수 있고, 권력이 커지며, 다른 사람들이 자신에게 의존하는 정도가 높아진다.
- 중심성은 조직 내의 인사 이동에 많이 활용된다.
- 연결 중심성 : 하나의 점에 얼마나 많은 다른 점들이 연결되어 있는가? 높을 수록 마당발로서 많은 관계를 맺고 있기 때문에 원하는 정보를 얻을 확률이 높고, 권력이 커지게 된다고 할 수 있다.
- 근접 중심성 : 한 점이 다른 점에 얼마나 가까운가를 나타내며, 연결망 내에 각 점에서 다른 점으로의 경로 거리를 나타낸다. 높을 수록 연결망 내에서 핵심이 되는 인물과 가까운 거리에 위치하고 있어 주요 정보와 권력을 확보할 수 있다.
- 매개 중심성 : 연결망 내에서 한 점이 다른 점들 사이에 위치하는 정도를 말하며, 한 점이 담당하는 중재자 역할의 정도를 나타낸다. 높을 수록 중재자로서 다른 행위자들이 의존하는 정도가 높아져서 그 사람의 영향력이 커지게 된다.
- 밀도 : 연결망 내에서 전체 구성원들이 서로 간에 얼마나 많은 관계를 맺고 있는 가를 나타낸다
- 네트워크 내에 존재하는 가능한 총 관계 수 중에서 실제로 맺어진 관계 수의 비율로 계산한다.
- 모든 구성원들이 상호 연결되어 있으면 네트워크의 밀도도 높고, 구성원들 간에 동일한 크기의 권력을 나누어 가질 확률이 높다. 하지만 일반적으로는 네트워크의 밀도는 상호 연결정도가 낮아서 네트워크의 밀도도 낮다고 할 수 있다.
- 밀도가 높은 집단일수록 정보의 교류와 확산 정도가 높고, 규범, 가치, 행동 패턴의 모방과 공유정도가 높다고 할 수 있다.
- 하지만 정보를 전달하는 사람의 입장에서 서로 간의 정보의 중복과 낭비가 발생하며, 커뮤니티 집단 내의 정보 보안에 대한 통제가 매우 어렵다
- 중심화 : 전체 연결망의 형태가 어느 정도 중앙에 집중되었는지를 나타내는 개념
- 방사선 형태의 연결망이 중심화가 가장 높은 연결망
- 중앙성이 어떤 결점이 연결망 내에서 얼마나 중심적인 위치를 차지하는가에 초점을 둔다면, 중심화는 한 연결망이 전체적으로 얼마나 중앙 집중적인 구조를 가졌는지, 혹은 연결망이 얼마나 한 점을 중심으로 결속되었는가를 측정하는것
- 구조적 틈새 : 한사람이 다른 사람들과의 연계에서 중복되지 않고, 그 행위자를 통해서만 다른 사람이 연계되는 바로 그 위치
- 구조적 틈새에 자리 잡은 행위자가 누리는 가장 중요한 효과는 정보 확보의 우월성으로 지적된다.
37번 문제
여섯 가지 종류의 닭 사료 첨가물의 효과를 비교하기 위한 데이터이다. 아래에 대한 설명으로 부적절한 것은 무엇인가?
1. weight의 중앙값은 258.0
2. weight의 평균은 261.3
3. feed는 범주형 변수
4. 약 25%(Q1)의 닭의 weight가 204.5보다 작다.
5. weight의 범위는 315이다.
38번 문제
아래는 R의 내장데이터인 cars에서 속도와 제동거리의 관계를 회귀모형을 ㅗ추정한 것이다. 아래의 내용 중 부적절한 것은 무엇인가?
1. 회귀계수는 5%수준에서 유의하다
2. 오차 분산의 불편추정량은 236.5이다
3. 전체 관측치 수가 49개이다 <- (1+48)+1=50이다
4. 결정계수는 약 0.65이다
39번 문제
아래의 지문에서 말하고 있는 시계열의 종류는 무엇인가?
안정 시계열 : 시간에 따라 일정한 통계적 특성을 가지는 시계열을 말한다.
- 평균 불변성 : 시간에 따라 평균이 변하지 않는다.
- 분산 불변성 : 시간에 따라 분산이 변하지 않는다
- 공분산 불변성 : 두 시점간의 공분산이 두 시점의 위치가 아니라 시간 차이에만 의존한다.
- 안정 시계열의 예로는 백색 잡음이 있다.
표준자기함수 : 데이터의 자기상관을 계산하는 함수다. 자기 상관은 시간 차이에 따른 시계열 값들 간의 상관 관계를 나타낸다.
- 시간 지연 : ACF는 다양한 시간 지연에 대해 자기 상관 계수를 계산한다.
- 자기 상관 계수 : -1 ~ +1 사이의 값을 가지며, 특정 지연에서의 자기상관 정도를 나타낸다
- ACF는 시계열 모델의 식별과 모수 추정에 유용한다
불안정 시계열 : 시간에 따라 통계적 특성이 변하는 시계열이다. 이러한 시계열은 평균, 분산, 공분산 등이 시간에 따라 달라질 수 있다. 불안정 시계열의 예로는 추세나 계절성이 있는 시계열이 있다. 불안정 시계열을 안정 시계열로 변환하기 위해 차분, 로그변환, 이동 평균을 사용할 수 있다.
이동평균 함수: 이동 평균 함수는 시계열 분석에서 잡음 제거와 데이터 평활화를 위해 사용된다.
- 단순 이동 평균
- 일정한 길이의 윈도우를 설정하고, 해당 윈도우 내의 데이터 값의 평균을 계산한다.
- 새로운 데이터 포인트가 추가되면 윈도우를 앞으로 이동시켜 새로운 평균을 계산한다.
- 가중 이동 평균
- 각 데이터 포인트에 가중치를 부여하여 평균을 계산한다.
- 최근 데이터에 더 큰 가중치를 부여하여, 최근 병화에 더 민감하게 반응하도록 한다
- 이동 평균함수는 시계열 데이터의 변동성을 줄이고, 추세와 패턴을 더 명확하게 파악하는데 유용
40번 문제
college 데이터 프레임은 777개 미국 소재 대학의 각종 통계치를 포함하고 있고 Books 변수는 평균적인 교재구입비용을 말한다. 미국 전체 대학의 평균 교재 비용에 대해 추론하려 할 때, 아래의 결과에 대한 설명으로 다음 중 적절하지 않은 것은 무엇인가?
1. 777개 대학의 평균 교재구입 비용은 549.38이다. (mean of x 549.381)
2. 대학의 평균 교재구입비용에 대한 점추정량은 549.38달러이다. (mean of x 549.381)
3. 대학의 평균 교재구입비용이 570 달러와 같다는 가설은 기각되지 않는다. <- 95 percent cofidence interval: 537.7537 561.0082에서 벗어나므로 기각된다.
4. 대학의 평균 교재구입비용에 대한 95% 신뢰구간은 (537.75,561.01)이다. (95 percent cofidence interval: 537.7537 561.0082)
단답 2번 문제
아래에서 언급한 것은 무엇인가?
CRM : 고객 관계 관리이며, 기업내부 데이터베이스 중 기업 전체가 경영자원을 효과적으로 이용하기 위해 통합적으로 관리하고 경영의 효율화를기하기 위한 수단으로 정보의 통합을 위해 기업의 모든 자원을 최적으로 관리하기 위한 기업 경영정보 시스템
SCM : 공급망관리이며, 공급업체, 구매기업, 유통업체, 물류회사들이 주문, 생산, 재고수준, 제품 및 서비스의 배송에 대한 정보를 공유하도록 하여 제품과 서비스를 효율적으로 구매, 생산, 배송할 수 있도록 지원하는 시스템
ERP : 전사적 지원 관리, 제조생산, 재무회계, 판매마케팅, 인적 자원 관리 등 비즈니스 프로세스들을 하나로 통합한 시스템
KMS : 지식관리 시스템, 기업의 우수한 지식을 활용하여 제품이나 서비스를 개발, 생산, 배송함으로서 경쟁기업보다 좋은 성과를 도모하기 위한 시스템
단답 3번 문제
다음 중 빈칸에 들어갈 알맞은 단어를 순서대로 적으시오
데이터 거버넌스란 전사차원의 모든 데이터에대하여 정책 및 지침, 표준화, 운용조직 및 책임등의 표준화된 관리체계를 수립하고 운영을 위한 프레임워크 및 저장소를 구축하는 것을 말한다. 특히 (마스터데이터),(메타데이터),(데이터사전)은 데이터 거버는서의 중요한 관리 대상이다.
단답 4번 문제
다음 중 빈칸에 들어갈 알맞은 단어를 적으시오
(시급성)은 전략적 중요도가 핵심이며, 이는 현재의 관점에서 전략적 가치를 둘 것인지, 미래의 중장기적 관점에 전략적인 가치를 둘 것인지를 고려하고, 분석 과제의 목표가치를 함께 고려하여 (시급성)의 여부를 판단할 수 있다.
단답 6번 문제
다수 모델의 예측을 관리하고 조합하는 기술을 메타학습이라 한다. 여러 분류기들의 예측을 조합함으로써 분류 정확성을 향상시키는 기법은?
앙상블 기법
단답 8번 문제
이산형 확률분포 중 주어진 시간 또는 영역에서 어떤 사건의 발생 횟수를 나타내는 확률 분포는?
포아송분포
단답 10번 문제
아래에서 언급한 것은 무엇인가?
- 데이터의 패턴을 발견하고 데이터 모델의 매개변수를 자동으로 학습한다.
- 자체 알고리즘을 사용하여 시간이 경과함에 따라서 경험을 축적하면서 작업 성능이 향상된다.
머신러닝
'공부 > ADsP' 카테고리의 다른 글
| 데이터 에듀 32회 오답노트 (1) | 2024.08.06 |
|---|---|
| 데이터에듀 31회 오답노트 (0) | 2024.08.04 |
| 데이터 에듀 39회 오답노트 (0) | 2024.07.26 |
| ADsP 데이터 에듀 모의1 오답노트 (1) | 2024.07.20 |
| ADsP 4장 2절 기초 통계분석 (0) | 2024.06.27 |



